
If you’ve ever run objdump on a Linux binary and seen puts@plt instead of a real address for puts, you’ve met the two quiet workhorses of every dynamically linked ELF program: the Procedure Linkage Table and the Global Offset Table. They’re the reason your 20 KB binary can still call into a 2 MB libc, the reason ASLR doesn’t break every program, and the reason attackers salivate when they see “No RELRO” in a checksec output.
In ELF executables, the Procedure Linkage Table (PLT) is a code section of small trampoline stubs that redirect external function calls, and the Global Offset Table (GOT) is a data section that stores the real runtime addresses of those functions. Together they implement dynamic linking: the PLT calls through the GOT, the dynamic linker patches the GOT with the real library address on first use, and every call after that jumps straight to the resolved function.
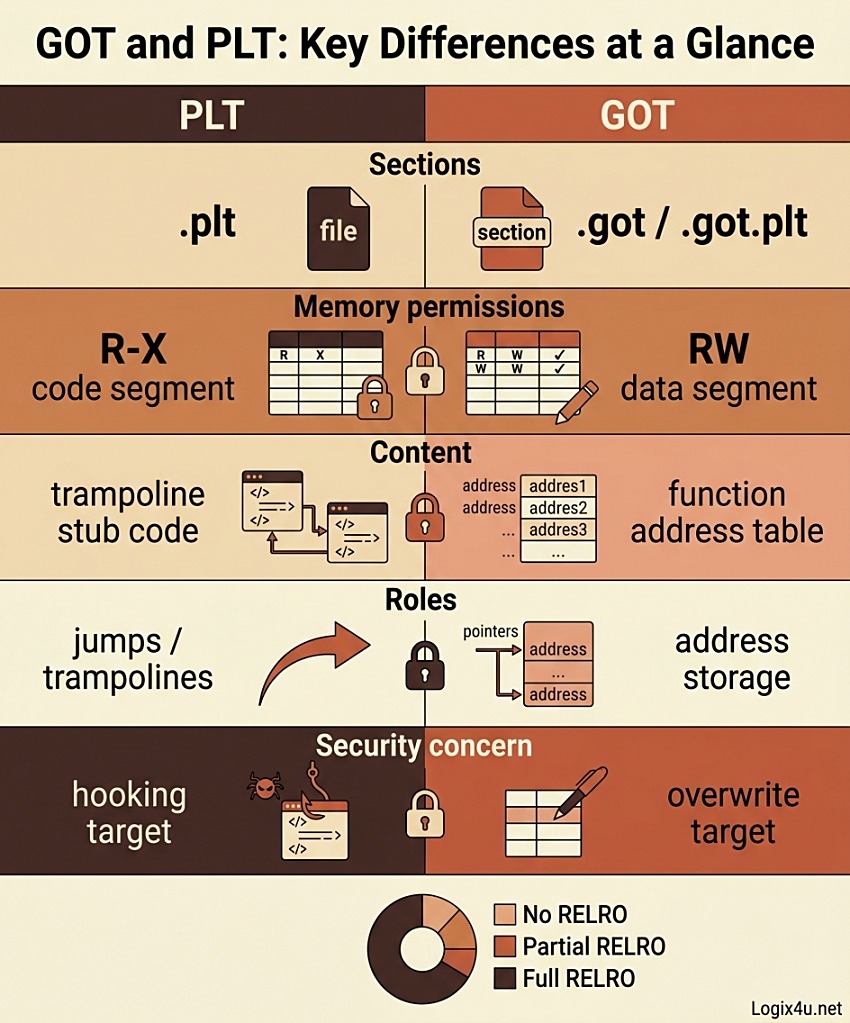
GOT vs PLT at a Glance
| Feature | PLT (Procedure Linkage Table) | GOT (Global Offset Table) |
|---|---|---|
| ELF section | .plt, .plt.sec, .plt.got | .got, .got.plt |
| Segment | Code (text) | Data |
| Memory permissions | R-X (read + execute) | RW initially, can be remapped R after RELRO |
| Contents | Trampoline stub instructions | Table of function and global variable addresses |
| Written by | Linker at link time | Dynamic linker (ld.so) at load or first call |
| Primary job | Jump target for external calls | Hold the resolved real address |
| Reverse-engineering value | Survives stripping, reveals libc usage | Reveals resolved libc addresses at runtime |
| Exploitation concern | PLT hijack, ret2plt | GOT overwrite, GOT hooking |
Keep this table in mind. Everything below is just filling in the why and how of each row.
Why ELF Executables Need the GOT and PLT in the First Place
To understand the GOT and PLT, you first have to understand the problem they solve.
Shared libraries exist to avoid duplication. Every Linux program that prints to the screen calls puts or printf. If every binary baked in its own copy of libc, the system would waste gigabytes and every libc security patch would require recompiling everything. So Linux uses dynamic linking: the binary just says “I need puts, please find it at runtime” and defers the actual address resolution to a helper program called the dynamic linker (ld.so or ld-linux.so.2).
But deferring resolution creates two headaches:
- ASLR randomizes load addresses. Every time your program runs, libc is mapped at a different virtual address. The binary can’t hardcode
puts‘s location, because that location changes on every execution. This is precisely the problem the Global Offset Table was designed to solve, enabling ELF programs to run correctly independent of the memory address where the program’s code or data is loaded at runtime. - The R^X principle says memory can be writable or executable, never both. That’s a core security guarantee: if the text segment were writable, an attacker who corrupted it could inject and run code directly. But if external function addresses need to be patched in at runtime, something has to be writable. The solution is to put the patchable data in a separate writable data section (the GOT) and keep the code section (including the PLT) read-only and executable. The PLT reads from the GOT; it never gets rewritten itself.
The GOT and PLT are the elegant compromise between these two constraints.
What Is the GOT (Global Offset Table)?
The GOT is a data table inside your ELF binary. Each entry is one pointer-sized slot, and each slot eventually holds the real runtime address of one external symbol (either a function or a global variable imported from a shared library).
Think of it as a phone book the program uses every time it wants to reach a library function. The binary doesn’t know the real extension, so it always looks up the number in the phone book. The dynamic linker is the receptionist who keeps that phone book up to date.
The GOT lives in two closely related sections:
.gotholds entries for imported global variables and, in some layouts, non-PLT function references..got.pltholds entries tied to PLT stubs, i.e. function addresses resolved through the lazy binding machinery.
The first three slots of .got.plt are reserved and have a specific layout. On x86-64, .got.plt[0] is the link-time address of _DYNAMIC, .got.plt[1] and .got.plt[2] are reserved by ld.so — .got.plt[1] is a descriptor of the current component while .got.plt[2]is the address of the PLT resolver. Every subsequent slot belongs to one imported function and gets resolved lazily or eagerly depending on the binding mode.
You can see the GOT directly:
readelf -r ./mybinary # show relocation entries for GOT slots
objdump -R ./mybinary # same, alternate format
objdump -s -j .got.plt ./mybinary # raw hex dump of the .got.plt section
The R_X86_64_JUMP_SLOT relocation type (or R_*_JMP_SLOT on other architectures) is the tell: that’s the dynamic linker’s marker saying “I’ll patch this slot at runtime.”
What Is the PLT (Procedure Linkage Table)?
The PLT is code, not data. It sits in the text (code) segment, is read-only and executable, and consists of short stubs, typically three or four assembly instructions each. Each PLT entry corresponds to one external function, like puts@plt, printf@plt, malloc@plt.
Here’s what a PLT stub does in practice on x86-64:
- Jump indirectly through the corresponding GOT slot.
jmpq *GOT[foo](%rip). - If the GOT slot is unresolved, fall through to code that pushes a relocation index onto the stack and jumps to the PLT header, which invokes the dynamic linker’s resolver.
- If the GOT slot is already resolved, the first indirect jump just lands directly in libc. Done.
Important nuance: foo@plt is not a real symbol. Tools like objdump and GDB display PLT stubs with that notation for readability, but there’s no symbol table entry called foo@plt. It’s just a conventional label for a linker-synthesized stub.
And the clever part: calling the PLT entry is functionally equivalent to calling the real function. That’s what makes the whole scheme transparent to the compiler. The compiler emits call puts and the linker silently rewrites it to call puts@plt. Your C code doesn’t have to know anything about this.
How the GOT and PLT Work Together: Lazy Binding Step by Step
This is the core interaction. Grab coffee.

When you call puts("Hello") in a dynamically linked binary using the default lazy-binding mode, here’s what happens the first time that call executes:
- Program calls
puts@plt. The compiler emittedcall putsand the linker redirected it to a PLT stub in.plt. - The PLT stub does an indirect jump through the GOT:
jmpq *GOT[puts](%rip). - The GOT entry for
putsinitially points back into the PLT itself, specifically to the instruction right after the first jump. That’s the key trick. The linker pre-loaded the GOT with “go to the lazy resolver” pointers. - Control lands on
push $reloc_indexfollowed by a jump to the PLT header (PLT[0]). - The PLT header pushes a descriptor and jumps to
_dl_runtime_resolvein ld.so. This is the dynamic linker’s function-resolving routine. - The dynamic linker searches the loaded shared libraries, finds
putsinside libc.so.6, and writes its real address into the GOT slot. This is what theR_X86_64_JUMP_SLOTrelocation targets. - The resolver tail-calls
putsso the user’s call proceeds as if nothing unusual happened.
On every subsequent call to puts, step 2 is the whole story: the GOT entry is already patched, so the indirect jump goes straight to libc with no overhead. One extra instruction cache line compared to a direct call. That’s it.
This is the central beauty of the design. The first call is expensive because the linker has to do real work. Every call after that is cheap.
.got vs .got.plt: Why Two Sections?
New readers get confused here. Two GOT-ish sections, similar names, overlapping purpose. Here’s the clean split:
.gotholds entries for data references (imported global variables) and for function references that don’t use lazy binding (for example, when-fno-pltor-z nowis in effect, or for non-PLT GOT accesses)..got.pltholds entries tied to PLT stubs. Its entries start life pointing back into the PLT for lazy resolution, then get patched with real libc addresses.
The split exists mostly for security hardening. With Full RELRO (-Wl,-z,relro,-z,now), the dynamic linker resolves everything eagerly at startup and then remaps the whole GOT (including .got.plt) read-only. With Partial RELRO, only .got becomes read-only, while .got.plt stays writable so lazy binding can still patch it. We’ll cover RELRO in more depth below.
Eager Binding vs Lazy Binding
Two operating modes, same infrastructure.
Lazy binding (the default on most glibc systems): symbols resolve on first use. Fast startup, but an error like “undefined symbol” can surface minutes into program execution when the offending function is finally called. You can force lazy binding with LD_BIND_NOW=0 or the linker flag -z lazy.
Eager binding (immediate binding): the dynamic linker resolves every external symbol before the program’s main runs. Slower startup, but any missing-symbol errors fail loudly at launch, and the GOT can be locked down immediately after. Trigger it with LD_BIND_NOW=1 at runtime or link with -Wl,-z,now. This is the model used by musl and Android bionic; in other ld.so implementations lazy binding is usually the default, but with the rise of security hardening on Linux distributions, many have switched to full RELRO linking.
Eager binding has a quiet bonus: it surfaces underlinking bugs. Lazy binding lets broken binaries run happily right up until they call the missing function and then crash.
Walking Through a Real ELF Binary
Let’s make this concrete. Save this as hello.c:
#include <stdio.h>
int main(void) {
puts("hello, world");
return 0;
}
Compile it:
gcc -o hello hello.c
Now inspect.
Step 1: see the PLT stub.
objdump -d -j .plt hello
You’ll see a PLT header followed by one entry per imported function. For puts, the key instruction is an indirect jump through a .got.plt offset.
Step 2: see the GOT relocations.
readelf -r ./hello
Look for a section labeled .rela.plt. Each entry pairs a GOT slot address with a symbol name (like puts) and a R_X86_64_JUMP_SLOT relocation type.
Step 3: watch lazy binding happen in real time.
LD_DEBUG=bindings ./hello
This prints a line every time the dynamic linker resolves a symbol, along with which library it came from. You’ll see putsgetting resolved from libc.so.6 exactly once.
Step 4: force eager binding and compare.
LD_BIND_NOW=1 LD_DEBUG=bindings ./hello
Now you’ll see every external symbol resolved before main runs.
Step 5: compare the binding mode with checksec.
checksec --file=./hello
This shows RELRO status, PIE, canaries, NX, and more — the one-shot picture of how hardened your binary is.
PLT Architecture Variations
The PLT looks different on every architecture, but the core idea (indirect jump through a GOT slot, lazy resolver fallback) is universal. A few highlights.
x86-64 uses PC-relative addressing, which makes the PLT compact and efficient. A typical .plt entry is 16 bytes: a single jmp *got.plt+offset(%rip) plus the lazy fallback tail. When Intel’s Indirect Branch Tracking (IBT) is enabled, the linker adds an extra .plt.sec section so all indirect jumps can land on endbr64 instructions.
AArch64 arguably has the cleanest PLT design. It uses adrp + ldr + br through x16/x17 registers. When Arm v8.5 Branch Target Enablement is in effect, every PLT entry needs a bti instruction. AArch64 also has a special variant procedure call standard: function symbols with the STO_AARCH64_VARIANT_PCS bit get resolved eagerly because the standard PLT resolver doesn’t preserve all the registers required for AdvSIMD and SVE vector calls.
RISC-V uses R_RISCV_CALL and R_RISCV_CALL_PLT and benefits from PC-relative addressing, so it avoids the non-PIC/PIC PLT split that plagues older architectures.
x86-32 (old but still out there) has no PC-relative memory load, so it has to keep the GOT base address in a callee-saved register (ebx) and reference GOT entries relative to that. This costs a general-purpose register and makes tail calls awkward.
PowerPC64 ELFv2 moves the TOC base setup from the call stubs to the function prologue, reducing PLT stub length at the cost of slower intra-component calls.
If you only ever reverse-engineer x86-64 Linux binaries, you can get away with knowing just the x86-64 layout. But understanding that the shape changes per architecture will save you confusion the first time you open an AArch64 Android binary or a RISC-V firmware image.
Security Implications: GOT Overwrites, PLT Hooks, and RELRO
The GOT is a tantalizing target for exploitation because it holds writable function pointers. If an attacker gets a write primitive (a heap overflow, a format-string bug, an integer overflow leading to out-of-bounds write), overwriting a GOT entry can redirect every subsequent call to a function of their choosing, typically system or execve.
Ret2plt is the complementary trick: instead of overwriting the GOT, the attacker builds a ROP chain that calls existing PLT stubs directly, for instance to leak a libc address and defeat ASLR.
Function hooking via the GOT is not just offensive; it’s also the backbone of legitimate dynamic-instrumentation tools. LD_PRELOAD lets you ship a shared library that defines, say, your own puts, and at startup the dynamic linker patches the GOT to point to your version instead of libc’s. Frida, ptrace-based debuggers, sandboxing tools, and malware sandboxes all lean on this mechanism.
RELRO (Relocation Read-Only) is the mitigation. Introduced to close the GOT-overwrite vector, it comes in three states:
- No RELRO: GOT is fully writable. Easiest to exploit. Rare on modern distros.
- Partial RELRO (linker flag
-Wl,-z,relro): The linker reorders sections so.gotcomes before.bssand.data, preventing buffer overflows in data from spilling into the GOT..gotis marked read-only after relocation, but.got.pltstays writable so lazy binding still works. This is the default on most modern Linux distributions. - Full RELRO (linker flags
-Wl,-z,relro,-z,now): Combines Partial RELRO with eager binding, then remaps the entireGOT read-only. No lazy binding, no GOT overwrite vector.
The trade-off is startup time. Full RELRO forces the dynamic linker to resolve every external symbol before main, which is fine for long-running daemons but noticeable for short-lived utilities. For anything security-sensitive, Full RELRO is the right default. You can read Red Hat’s original technical breakdown of RELRO hardening for the historical context and measurement details.
Check the RELRO state of any binary with:
checksec --file=./mybinary
readelf -l ./mybinary | grep -i relro
Look for a GNU_RELRO program header. If it’s there and BIND_NOW is set in .dynamic, you have Full RELRO.
-fno-plt: Skipping the Trampoline Entirely
Since GCC 6.0, the compiler flag -fno-plt tells the toolchain to skip the PLT stub and call through the GOT directly. The generated code sequence on x86-64 looks like:
call *puts@GOTPCREL(%rip)
That’s one instruction instead of a call into .plt followed by the indirect jump inside the stub. You can read more about this option in the official GCC code generation options documentation. -fno-plt disables lazy binding for those call sites (they’re resolved eagerly), so it pairs naturally with Full RELRO hardening.
When is -fno-plt worth it? Short answer: when most of your calls are to shared library functions and you’ve already committed to eager binding anyway. It shaves one instruction per call. If that matters for your workload, measure and decide. For most applications, the default PLT scheme is fine.
Why This Matters for Reverse Engineers
If you do malware analysis, exploit development, or binary research, the GOT and PLT are probably the two most useful landmarks in an unknown binary.
In stripped binaries, the PLT survives. Even when every internal symbol is gone, the PLT stubs retain their structure and their relocation entries still name the external functions. A single objdump -d -j .plt stripped.bin plus readelf -r stripped.bingives you a list of which libc functions the binary uses. That’s often enough to tell you whether you’re looking at a network daemon (socket, bind, accept), a crypto tool (EVP_*), a shell (execve, fork), or a file-exfiltrator (open, read, fwrite).
In running processes, the GOT reveals resolved addresses. Attaching GDB and dumping .got.plt shows exactly where every library function landed in memory this run. That’s one of the cleanest ways to bypass ASLR during dynamic analysis or to build a custom hook.
In exploitation, both tables are primary targets. The GOT gives you writable function pointers (if RELRO doesn’t cover it). The PLT gives you ready-made gadgets to call libc functions without first leaking their addresses.
Common Mistakes and Pitfalls
A few recurring sources of confusion:
- Confusing
.gotwith.got.plt. They’re related but distinct..gotis for general imported data and non-PLT function references..got.pltis the one that works in tandem with the PLT for lazy function resolution. - Thinking
foo@pltis a real symbol. It’s a display convention fromobjdump/GDB. The PLT has no symbol table entries of its own. - Assuming every ELF has a PLT. Static executables don’t need GOT or PLT because there are no external calls to resolve. Executable files that do not depend on external libraries, then no relocations should be pending for them as they can load without external objects, do not need .dynamic, GOT, or PLT, as function calls are done directly to the function address without any intermediate.
- Confusing lazy binding with laziness in general. Lazy binding is specifically about deferring symbol resolution. Code itself is mapped into memory eagerly. The GOT is what gets populated on demand.
- Forgetting that shared libraries have their own GOTs. When you enable Full RELRO, only the main executable’s GOT becomes read-only. GOTs inside loaded shared libraries may still be writable unless those libraries were also compiled with Full RELRO.
Pro Tips for Working With the GOT and PLT
A handful of things I wish someone had told me earlier:
- Use
LD_DEBUG=allsparingly,LD_DEBUG=bindingsoften.bindingsalone gives you the exact symbol resolution trace without drowning you in unrelated output. LD_PRELOADwith a custom.sois the cheapest way to hook a function without touching the binary. Define your replacement, usedlsym(RTLD_NEXT, "funcname")to call the real one, and you have a drop-in interceptor.lddlies sometimes. It runs the binary to trace imports. For untrusted binaries, usereadelf -d ./bin | grep NEEDEDinstead.- Always check RELRO before attacking the GOT. Full RELRO kills classic GOT-overwrite exploits. If you see it, look for other writable code pointers (vtables,
__fini_array,__malloc_hookin older glibc). - For performance-sensitive shared libraries, compile with
-fvisibility=hidden. It reduces the number of symbols that need to go through the GOT at all.
Tools and Resources
| Tool | What it shows |
|---|---|
objdump -d -j .plt <bin> | PLT stub disassembly |
objdump -R <bin> | Dynamic relocations (GOT entries) |
readelf -r <bin> | Full relocation table |
readelf -d <bin> | Dynamic section (shared library dependencies, flags) |
readelf -l <bin> | Program headers including GNU_RELRO |
checksec --file=<bin> | Quick RELRO/PIE/canary/NX summary |
LD_DEBUG=bindings ./bin | Live symbol resolution trace |
LD_BIND_NOW=1 ./bin | Force eager binding |
gdb ./bin + info functions | Inspect PLT entries at runtime |
pwntools ELF(...) | Python-friendly GOT/PLT access for exploitation |
For the formal specification, the Linux Foundation ELF reference specs are the authoritative source on section layouts, relocation types, and dynamic linker behavior across architectures. The Wikipedia Global Offset Table page gives a concise general overview if you want a lighter-weight primer.
Frequently Asked Questions
What is the difference between GOT and PLT in ELF?
The PLT is code (trampoline stubs in the .plt section) that redirects calls to external functions. The GOT is data (address entries in the .got and .got.plt sections) that stores the resolved runtime addresses of those functions. The PLT jumps through the GOT. The GOT holds the real addresses. They work together to make dynamic linking work without compromising the read-only-code security model.
Is the PLT read-only?
Yes. The PLT lives in the text segment of the ELF, which is mapped read-only and executable (R-X). This is by design: PLT stubs are code, and code shouldn’t be writable. All the runtime patching happens in the GOT, not the PLT.
Can the GOT be made read-only?
Yes, through RELRO (Relocation Read-Only). With Full RELRO (-Wl,-z,relro,-z,now), the dynamic linker resolves every symbol at startup and then remaps the entire GOT read-only before main runs. With Partial RELRO, only .got is read-only while .got.plt stays writable to support lazy binding.
What is lazy binding?
Lazy binding is the default symbol resolution strategy in glibc. Instead of resolving every external symbol at program startup, the dynamic linker leaves the GOT entries pointing at a resolver stub. The first call to each function goes through the resolver, which patches the GOT with the real address. Every subsequent call uses the cached address directly. This improves startup time at the cost of a tiny per-function first-call penalty.
Does a static executable have a GOT and PLT?
No. Static executables embed all their dependencies, so there are no external symbols to resolve at runtime. They don’t need a dynamic linker, a GOT, a PLT, or the .dynamic section. Function calls go directly to the target address.
What does puts@plt mean in GDB or objdump?
It’s a display convention. puts@plt refers to the PLT stub for the puts function. It is not a real symbol table entry; objdump and GDB generate that label for readability so you can tell where each PLT slot sends calls.
How do attackers abuse the GOT?
The classic attack is a GOT overwrite. If an attacker has an arbitrary write primitive and the binary has No or Partial RELRO, they can overwrite a GOT entry (say, the slot for puts) with the address of system. The next call to puts("something")then jumps to system("something") instead. Full RELRO blocks this by making the GOT read-only before user code runs.
What is _dl_runtime_resolve?
It’s the internal glibc function that resolves symbols during lazy binding. When a PLT stub fires the first time and finds an unresolved GOT entry, control ends up in _dl_runtime_resolve. It reads the relocation index from the stack, looks up the target symbol in the loaded shared libraries, patches the GOT, and jumps to the resolved function.
Does ASLR affect the GOT and PLT?
ASLR randomizes where shared libraries load, which means the actual function addresses change every run. The GOT is specifically designed to absorb this: the binary doesn’t hardcode libc addresses, it just reads whatever the dynamic linker wrote into the GOT slot. The PLT itself lives inside the binary, so with PIE enabled, its location is also randomized along with the rest of the executable.
What tools do I use to inspect the GOT and PLT?
objdump -d -j .plt, objdump -R, readelf -r, readelf -d, and checksec are the core command-line tools. For runtime inspection use GDB with disassemble and x/gx against GOT addresses, or run the binary with LD_DEBUG=bindings. For exploitation work, pwntools in Python exposes elf.got and elf.plt as dictionaries keyed by symbol name.
Next Steps
If you want to go deeper, here’s a reasonable progression:
- Build a toy C program and work through every command above (
objdump,readelf,LD_DEBUG) until each output makes sense. - Read the Linux Foundation ELF specification for your target architecture. The x86-64 psABI is the most widely useful starting point.
- Try a beginner binary exploitation challenge that involves a GOT overwrite or ret2plt. Picking up
pwntoolshere is a force multiplier. - If you’re into toolchain internals, read the GCC code generation options documentation and experiment with
-fno-pltand-fvisibility=hiddento see how the generated code changes. - Inspect the RELRO state of the binaries on your own Linux system. You’ll find a mix, and the reasons behind the mix are instructive.
Save this guide if you work with ELF binaries regularly. The GOT and PLT look intimidating the first time, but once the mental model clicks, every unfamiliar piece of dynamic linker output becomes easy to read.